

SuperCLUE评测发布:山海大模型实力凸显,位列全球顶尖
品牌企业 2024-07-15 gusd68687
7月9日,SuperCLUE发布《中文大模型基准测评2024上半年报告》,报告选取国内外有代表性的33个大模型在6月份的版本,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。
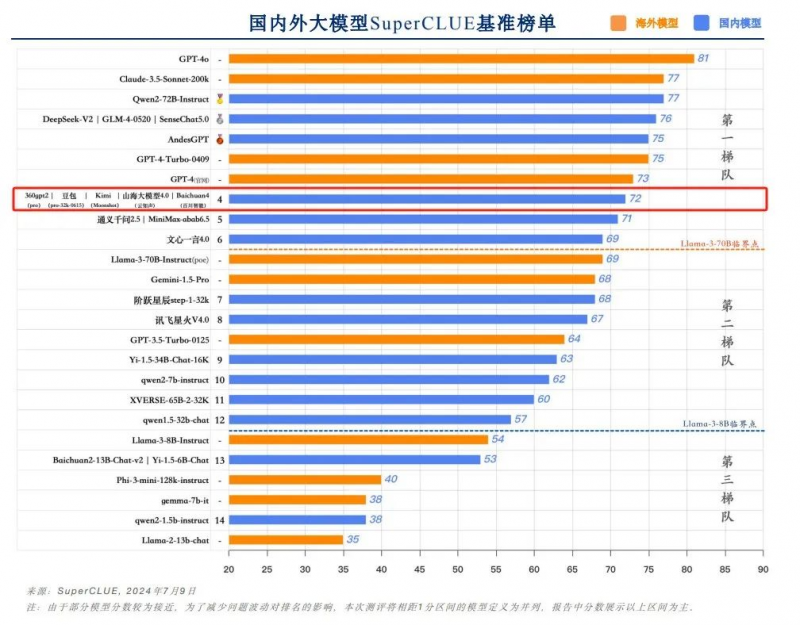
报告显示,云知声山海大模型在本次半年度评测中取得总分72的优异成绩,与360gpt2-pro、字节跳动豆包、月之暗面Kimi、百川智能Baichuan4并列国内大模型第四,稳居全球大模型第一梯队。
SuperCLUE作为国内权威通用大模型综合性测评基准,其前身可追溯至第三方中文语言理解评估基准CLUE(The Chinese Language Understanding Evaluation)。自2019年成立以来,CLUE基准一直致力于提供科学、客观、中立的语言模型评测,其先后推出了CLUE、FewCLUE、KgCLUE、DataCLUE等多个被广泛认可的评估标准。根据CLUE多年测评经验,SuperCLUE基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准。
作为一个完全独立的第三方评测机构,SuperCLUE采用自动化评测技术,有效消除人为因素带来的不确定性,确保提供无偏倚的客观评测结果。不同于传统测评通过选择题形式的测评,SuperCLUE纳入开放主观问题的测评,通过多维度多视角多层次的评测体系以及对话的形式,模拟大模型的应用场景,真实有效考察模型生成能力。与此同时,SuperCLUE根据全球的大模型技术发展趋势,不断升级迭代测评体系、测评维度和方法,以保证尽可能精准量化大模型的技术演进程度。
为进一步真实反映大模型能力,本次通用测评采用多维度、多层次的综合性测评方案,由理科、文科和Hard三大维度构成:理科任务分为计算、逻辑推理、代码测评集;文科任务分为知识百科、语言理解、长文本、角色扮演、生成与创作、安全和工具使用七大测评集;Hard任务聚焦精确指令遵循测评集,未来将陆续推出复杂多步推理和高难度问题解决等评测。

从代表通用能力的一级总分来看,山海大模型得分72,与360gpt2-pro、字节跳动豆包、月之暗面Kimi、百川智能Baichuan4并列国内大模型第四,位居全球大模型第一梯队。
具体到二级维度得分,山海大模型在理科和文科领域均表现优异——在理科能力方面,山海大模型以76分的高分紧随GPT-4o、GPT-4-Turbo-0409之后,力压一众国内大模型,并列排名国内第一;文科能力以75分的成绩并列国内第二,实力同样不容小觑。


在SuperCLUE基于基础能力和应用能力两个维度构建的模型象限图中,山海大模型被定位为“卓越领导者”。这一分类反映了山海大模型在基础和场景应用能力上均达到了领先水平,持续引领国内大模型技术发展和创新。

此外,与GPT4-Turbo-0409的对战胜率统计数据显示,山海胜率为17.67%,和率为65.37%,位列国内大模型第五,整体实力依旧不俗。

自2023年5月问世以来,山海大模型已相继在C-Eval全球大模型综合性评测、OpenCompass大模型评测、MedBench评测等多个权威评测中屡创佳绩,充分展现出业界一流的通用能力和领先于世界的行业大模型能力。
正如报告所言,随着技术进步和应用场景拓展,2024年下半年国内外大模型市场竞争将持续加剧,推动技术创新和产业升级。接下来,云知声将继续保持大模型能力稳步提升,以山海为抓手,在产业侧实现加速落地,致力成为真正助力各行各业的“新质生产力”。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
The End
免责声明:本文内容来源于第三方或整理自互联网,本站仅提供展示,不拥有所有权,不代表本站观点立场,也不构成任何其他建议,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容,不承担相关法律责任。如发现本站文章、图片等内容有涉及版权/违法违规或其他不适合的内容, 请及时联系我们进行处理。
相关阅读
- 提升办公效率,除了钉钉和企业微信,还可以选择什么工具?
- 年终大促,这几款爱依瑞斯皮床让你尽享品质生活!
- 白鹿穿露胃装搭配长裤还是短裙好看?白鹿这样穿露胃装性感显腿长
- 康姿百德:老年人床垫,也要精挑细选
- 俄罗斯和朝鲜签署重磅条约!普京已于凌晨抵达越南
- 端午节放3天不调休 2024年端午假期正常连休不调休
- 发重磅新品、携手中华老字号,合和昌成功参展2023广州秋季茶博会
- 常州曙光医疗美容医院 3月8日 聚焦新品|轮廓固定 璀璨美学!乔亚璀璨新品发布会
- airyou fly1对比airpods pro 2,今年旗舰tws耳机该选谁?
- 荣耀官宣沈腾成为荣耀AI大使!荣耀Magic7系列率先搭载YOYO智能体
-
分类导航
-
-
最新文章
-
本栏文章
-
随机文章
-
友情链接
